
- 병렬성이 빅데이터를 가능하게 한다.
- 여러개의 컴퓨팅 자원을 동시에 활용할 수 있어야만 테라바이트 수준의 데이터를 처리할 수 있다.
- 수백대의 컴퓨터가 구성하는 클러스터에서 데이터와 연산 자체를 분산시키면서 수행한다.
- 즉, 데이터 병렬성을 활용한다.
- 맵 리듀스
- 데이터에 맵을 적용한 다음 출소 함수를 적용하고, 그것을 여러 대의 컴퓨터로 이뤄진 클러스터로 분산시킨다.
- 위 의미를 가지는 맵리듀스는 대표적으로 하둡이 있다.
하둡 기본
![]()
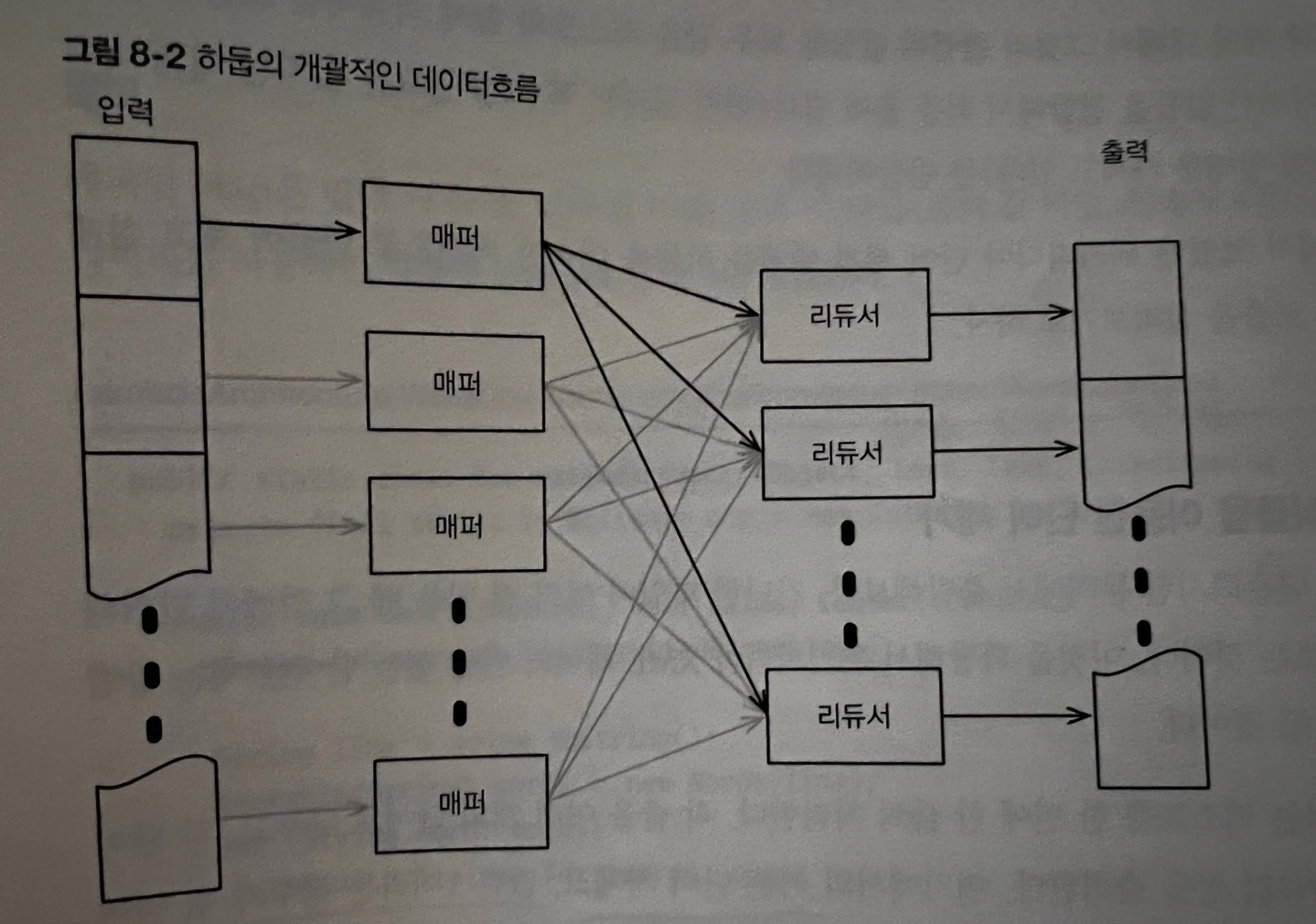
- 위 이미지와 같이 매퍼와 리듀서는 여러대의 물리적인 컴퓨터에 분산된다.
- 맵리듀스 업무는
매퍼와리듀서라는 두개의 특정한 컴포넌트로 구성됨- 매퍼
- 입력 포맷을 받아들여서 여러 개의 키/값 쌍으로 변환시킨다
- 리듀서
- 이러한 키/값 쌍을 받아들여서 최종적인 출력 포맷으로 전환시킨다.
- 매퍼와 리듀서가 동일한 개수여야한다는 규칙은 없다.
- 매퍼
- 하나의 매퍼가 만들어내는 키/값 쌍들은 다시 여러개의 리듀서에 전달된다.
- 어떤 리듀서가 어떤 키/값 쌍을 전달받는지는 키에 의해서 전달된다.
- 하둡은 동일한 키를 사용하는 쌍들을 그것들이 어떤 매퍼가 만들었는지와 관계없이 언제나 동일한 리듀서에 의해서 처리되는것을 보장한다 → shuffle 단계라고 불린다.
- 전통적인 데이터 시스템의 문제
- 전통적인 데이터베이스는 오늘날도 너무 잘 쓰이고 있고 잘 동작했지만 오늘날 같이 데이터가 너무 많고 큰 경우에는 힘든 경우가 많다.
- 규모
- 복제나 샤딩을 하면 전통적인 데이터 베이스도 성능 개선이 되지만 점점 컴퓨터 대수가 많아지고 질의양도 커지면 결국 한계가 온다.
- 유지보수 오버헤드
- 여러대의 컴퓨터에 퍼져있는 DB를 관리하는건 어렵다.. 예를 들면 DB를 재샤딩하는 경우.. 장애 허용, 백업, 데이터 무결성 보장 등.. 질의 규모가 커짐에 따라 이런 모든 일들을 다 챙기는 건 너무 어려운 일이다.
- 복잡성
- 복제, 샤딩 등 을 하면 우선 복잡해지고 개발자들도 트랜잭션 관리등 .. 복잡해진다.
- 휴먼에러
- 관리를 잘하거나 문제가 생겼을때 복구를 바로바로 한다해도 이런걸 오로지 사람에게 맡기고 휴먼에러가 안나길 운에 기대는건 바람직하지 않음
- 규모
- 전통적인 데이터베이스는 오늘날도 너무 잘 쓰이고 있고 잘 동작했지만 오늘날 같이 데이터가 너무 많고 큰 경우에는 힘든 경우가 많다.
- 불멸의 진리
- 정보는 2가지로 나눌 수 있다.
- 원천 데이터
- 도출된 데이터
- ex)
- 계좌
- 입금, 출금 : 원천 데이터
- 잔액 : 도출된 데이터
- 계좌
- 원천데이터는 불변이고 영원한 사실이다
- 도출된 데이터는 따로 관리할 필요없이 원천데이터로 도출시키면 됨
- 원천 데이터가 좋은이유?
- 불변하다는건 병렬처리가 가능하다는 것 (불변과 병렬은 궁합이 넘 좋다)
- 그렇다면 원천 데이터만 저장하면 될까?
- 굳이 도출된 데이터를 따로 보관할 필요가 없다?
- 잠금장치를 둘러싼 메커니즘.. 혹은 트랜잭션 같은 복잡한게 필요없네?
- 이유는 한번 저장된건 변하지 않기 때문이지
- 더 좋은 일은 데이터가 불변이면 여러 개의 쓰레드가 서로를 방해할 걱정 없이 동일한 데이터에 마음껏 병렬적으로 접근할 수 있다는 점
- 이렇게 되면 이런 데이터를 클러스터 전체게 분산 시키는건 쉬운일!
- 정보는 2가지로 나눌 수 있다.
맵 리듀스, 데이터 병렬성 - Hadoop
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.
Comments powered by Disqus.